How to Scrape DoorDash Listings, Stores, Restaurants, and More w/ Python
DoorDash moves millions of orders every day; groceries, fast food, alcohol, pet supplies, and everything in between.
For businesses working in delivery, retail intelligence, or market research, this data is gold.
But DoorDash doesn’t give up its data easily. It’s protected behind Cloudflare, locked behind backend address validation, and scattered across different endpoints depending on whether you’re scraping a local restaurant or a national chain.
But we didn’t craft this detailed guide for nothing :)
Find ALL WORKING CODE on this GitHub folder ⚙
In this guide, we’ll scrape restaurant listings, menus, catalogs, and more after setting up an address on the backend, using Scrape.do for bypassing Cloudflare protection, all in simple Python scripts.
Starting with the most crucial step:
Why is Scraping DoorDash Difficult?
From a business perspective, it makes sense to block scrapers; menus, delivery zones, pricing, and reviews are constantly changing and highly localized.
Opening up that data means opening the door to competitor tracking, shadow apps, and data resellers.
So they’ve built real barriers. Not simple obfuscation mind you; real protection.
Heavy Cloudflare Protection Against Bots
DoorDash sits behind one of the strictest Cloudflare configurations I’ve seen.
In addition to regular challenges, it checks for TLS fingerprint mismatches, header consistency, browser quirks, and most importantly IP reputation.
Cloudflare sits at the door of DoorDash like Cerberus.
We’ll solve this challenge by using a scraping proxy like Scrape.do, which automatically handles TLS fingerprinting, header spoofing, and IP rotation behind the scenes for straight access.
You Need to Submit Your Address on the Backend
First thing DoorDash asks you when you pull up their homepage:
Your address.
The platform won’t return any real store data unless you pick a full address (with street, city, state, and ZIP) on the frontend and then submit it through their backend.
When you enter an address on the homepage, it sends a backend request, validates the address, and attaches it to your active session.
That session (and its attached address) is required to fetch any listings, menus, or delivery options. Scrape.do will also come in extremely handy for sticky sessions.
In fact, that’s what we’ll start our guide with:
Adding Your Address to DoorDash via Backend
To scrape anything meaningful from DoorDash (restaurants, menus, catalogs), you first need to attach an address to your session.
But this isn’t handled via the URL or any visible parameters.
Instead, DoorDash sends a GraphQL mutation behind the scenes that registers the address to your session.
That’s what we’ll replicate now using:
requeststo send the POST requestjsonto construct the payloadScrape.doto handle Cloudflare, TLS, sticky sessions, and header spoofing
You’ll also need your Scrape.do API token. If you don’t have one yet, sign up here for 1000 free credits.
Step 1: Finding the GraphQL Mutation
When you enter an address on the DoorDash homepage, your browser sends a backend request to:
https://www.doordash.com/graphql/addConsumerAddressV2?operation=addConsumerAddressV2
This is a POST request; which means instead of just fetching data, it’s sending data to the server to register your address with your session.
The data sent by you through this POST request is called the payload it travels in the body of the request, not in the URL, which is why it’s a next-level concept for web scraping.
To view and copy the payload:
Right-click and Inspect before visiting the DoorDash homepage or any page of the website. Open the Network tab in the developer tools that pop up and make sure Preserve log option in the top toolbar is checked (so that requests are not cleared when the new page loads.)
Pick an address (preferably somewhere DoorDash is available in) and then save it.
Now, your browser will send the POST request we just talked about. Once the new page loads, search for addConsumerAddress… from the top toolbar. Here’s what you should be able to see:
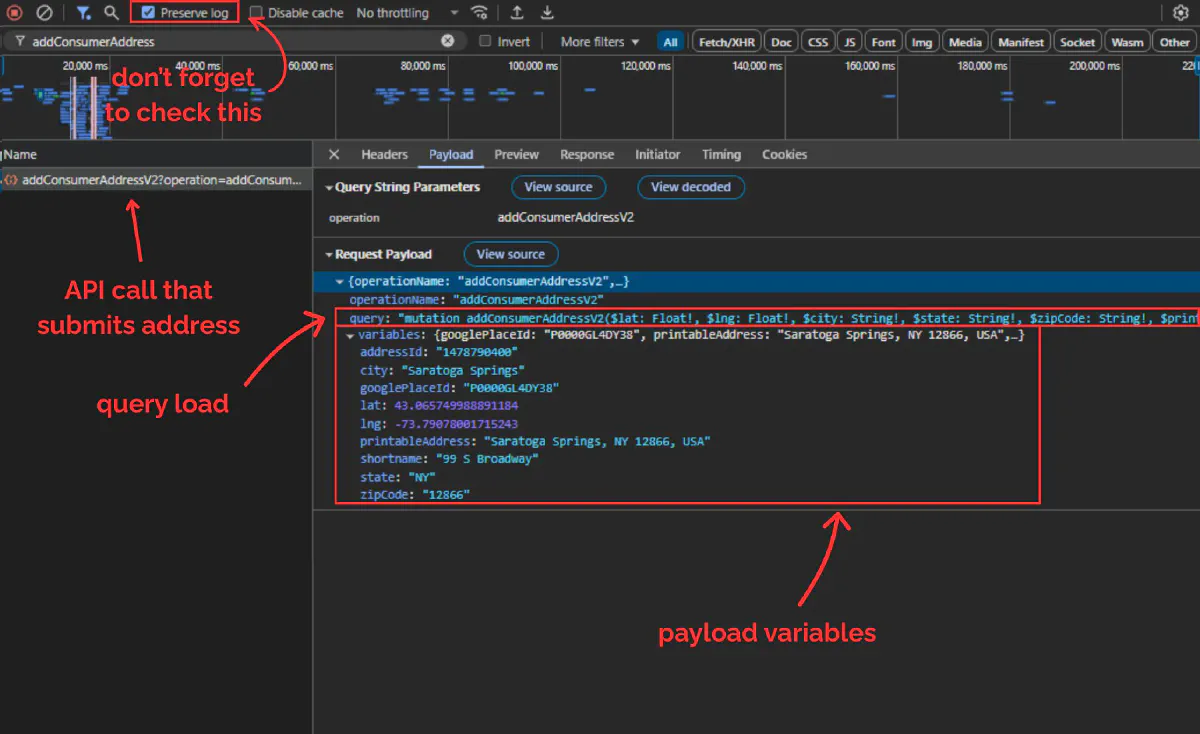
DoorDash uses a system called GraphQL, which always sends two things in the payload:
query: a big string that defines what operation to run (in this case,addConsumerAddressV2)variables: a JSON object containing all the real values (latitude, longitude, city, zip, etc.)
Is understanding what you see on this screen very helpful for web scraping projects?
Yes.
Do you need to understand it to scrape DoorDash?
Nope.
So for now, just being able to access this payload is enough, now we’ll replicate this POST request one-to-one.
Step 2: Rebuilding the Request in Python
We’ll now send the exact same POST request that the browser sends, but from Python.
We do this by constructing a POST request with two components:
- the target URL, which is the DoorDash GraphQL endpoint
- the payload, which contains both the
querystring and thevariables(your address data)
But instead of sending it directly, we’ll pass everything through Scrape.do to handle bypassing Cloudflare, spoof the headers and TLS fingerprint, and keep the session alive.
Here’s the full structure:
import requests
import json
# Scrape.do API token and target URL
TOKEN = "<your-token>"
TARGET_URL = "https://www.doordash.com/graphql/addConsumerAddressV2?operation=addConsumerAddressV2"
# Scrape.do API endpoint
api_url = (
"http://api.scrape.do/?"
f"token={TOKEN}"
f"&super=true"
f"&url={requests.utils.quote(TARGET_URL)}"
)
Then we define the payload we copied from what the browser sent (I’m adding the full payload here with Python dict, so bear with me):
payload = {
"query": """
mutation addConsumerAddressV2(
$lat: Float!, $lng: Float!, $city: String!, $state: String!, $zipCode: String!,
$printableAddress: String!, $shortname: String!, $googlePlaceId: String!,
$subpremise: String, $driverInstructions: String, $dropoffOptionId: String,
$manualLat: Float, $manualLng: Float, $addressLinkType: AddressLinkType,
$buildingName: String, $entryCode: String, $personalAddressLabel: PersonalAddressLabelInput,
$addressId: String
) {
addConsumerAddressV2(
lat: $lat, lng: $lng, city: $city, state: $state, zipCode: $zipCode,
printableAddress: $printableAddress, shortname: $shortname, googlePlaceId: $googlePlaceId,
subpremise: $subpremise, driverInstructions: $driverInstructions, dropoffOptionId: $dropoffOptionId,
manualLat: $manualLat, manualLng: $manualLng, addressLinkType: $addressLinkType,
buildingName: $buildingName, entryCode: $entryCode, personalAddressLabel: $personalAddressLabel,
addressId: $addressId
) {
defaultAddress {
id
addressId
street
city
subpremise
state
zipCode
country
countryCode
lat
lng
districtId
manualLat
manualLng
timezone
shortname
printableAddress
driverInstructions
buildingName
entryCode
addressLinkType
formattedAddressSegmentedList
formattedAddressSegmentedNonUserEditableFieldsList
__typename
}
availableAddresses {
id
addressId
street
city
subpremise
state
zipCode
country
countryCode
lat
lng
districtId
manualLat
manualLng
timezone
shortname
printableAddress
driverInstructions
buildingName
entryCode
addressLinkType
formattedAddressSegmentedList
formattedAddressSegmentedNonUserEditableFieldsList
__typename
}
id
userId
timezone
firstName
lastName
email
marketId
phoneNumber
defaultCountry
isGuest
scheduledDeliveryTime
__typename
}
}
""",
"variables": {
"googlePlaceId": "D000PIWKXDWA",
"printableAddress": "99 S Broadway, Saratoga Springs, NY 12866, USA",
"lat": 43.065749988891184,
"lng": -73.79078001715243,
"city": "Saratoga Springs",
"state": "NY",
"zipCode": "12866",
"shortname": "National Museum Of Dance",
"addressId": "1472738929",
"subpremise": "",
"driverInstructions": "",
"dropoffOptionId": "2",
"addressLinkType": "ADDRESS_LINK_TYPE_UNSPECIFIED",
"entryCode": ""
}
}
Then encode the payload data and send the request.
From the response, only thing we’re interested in is the scrape.do-rid response header so we print that out:
response = requests.post(api_url, data=json.dumps(payload))
scrape_do_rid = response.headers.get("scrape.do-rid")
print(f"scrape.do-rid: {scrape_do_rid}")
scrape.do-rid value identifies your session that’s created in Scrape.do’s cloud, and if the post request was successful this session will have the address we sent through the payload registered, giving us access to DoorDash.
The response should look like this:
scrape.do-rid: 4f699c-40-0-459851;
To keep using this session, we only need the last 6 digits (e.g. 361979) and we’ll need to carry that forward in every future request.
⚠ Scrape.do sessions will remain active while your requests are successful, but they will eventually shut down or DoorDash will flag your session as spam and block it out. Make sure to renew sessions on a regular basis to stay unblocked.
Scrape All DoorDash Restaurants and Stores for a Location
Using our session with an address registered, we can scrape all stores available for that location.
DoorDash exposes this through, again, a GraphQL endpoint called homePageFacetFeed.
This is what powers the homepage restaurant feed after you select an address.
Our goal in this section is to:
- Send a
POSTrequest tohomePageFacetFeedusing our existing session ID to get first batch of stores - Save the raw JSON response (which contains dozens of storefronts) to a local file
- To get all remaining stores edit the cursor variable and loop through all batches
- Finally, parse relevant store information and export all details to a CSV document
💡 Open and available stores and restaurants change during the day or different days of the week, to make sure you get all the data you might want to run your scraper hourly/daily during the week.
Get Query Payload for homePageFacetFeed Request
This is a step you’re familiar with.
To get the payload we’ll use in our script, make sure the address set in your browser is the same one you used to generate the session ID from addConsumerAddress.
Then:
- Visit the DoorDash homepage (or refresh it)
- Open DevTools → Network tab
- Search for
homePageFacetFeed
From there, extract the query and variables fields from the Payload tab just like we did earlier. We’ll use this in our next (and every request we make to this API endpoint).
Build Request and Print First Batch of Stores
Now let’s replicate the homePageFacetFeed request in Python.
We’ll send the same query and variables you copied earlier from DevTools — but route it through Scrape.do using the session ID from your addConsumerAddress step. This session ID keeps our context intact, so DoorDash knows which address we’re trying to fetch store data for.
Start by importing the necessary libraries and defining the basic config. You’ll need your Scrape.do token, the session ID (the last 6 digits from the previous step), and the target GraphQL endpoint:
import requests
import json
TOKEN = "<your-token>"
SESSION_ID = "<session-id>" # e.g. "459851"
TARGET_URL = "https://www.doordash.com/graphql/homePageFacetFeed?operation=homePageFacetFeed"
API_URL = f"http://api.scrape.do/?token={TOKEN}&super=true&url={TARGET_URL}&sessionId={SESSION_ID}"
Now, take the full GraphQL query string and the variable set you copied from your browser, and plug them in as the request payload:
payload = {
"query": "{full-payload-from-prev-step}",
"variables": {
"cursor": "eyJvZmZzZXQiOjAsInZlcnRpY2FsX2lkcyI6WzEwMDMzMywzLDIsMyw3MCwxMDMsMTM5LDE0NiwxMzYsMjM1LDI2OCwyNDEsMjM2LDIzOSw0LDIzOCwyNDMsMjgyXSwicm9zc192ZXJ0aWNhbF9wYWdlX3R5cGUiOiJIT01FUEFHRSIsInBhZ2Vfc3RhY2tfdHJhY2UiOltdLCJsYXlvdXRfb3ZlcnJpZGUiOiJVTlNQRUNJRklFRCIsImlzX3BhZ2luYXRpb25fZmFsbGJhY2siOm51bGwsInNvdXJjZV9wYWdlX3R5cGUiOm51bGwsInZlcnRpY2FsX25hbWVzIjp7fX0=",
"filterQuery": "",
"displayHeader": True,
"isDebug": False
}
}
Finally, send the request.
We’re not going to parse or print anything yet; instead, we’ll write the entire response to a file so we can make sure we’re getting stores in our response:
response = requests.post(API_URL, data=json.dumps(payload))
response.raise_for_status()
data = response.json()
with open("restaurants_first_batch.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print("Saved first page response to restaurants_first_batch.json")
The result must be a full JSON dump of the first batch of restaurants and storefronts DoorDash returned for your location, over 20K lines of JSON entries.
To make sure, check for the top restaurants that you see on your browser and see if they’re somewhere inside the JSON dump:
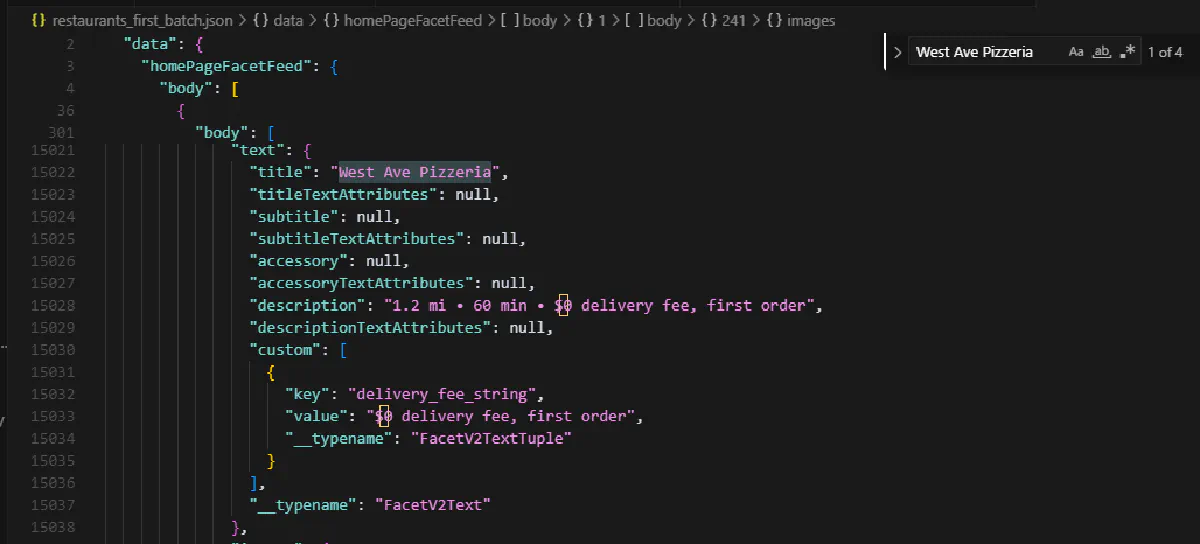
Once you’re positive you’re hitting the right API endpoint with right payload and session ID, it’s time to go for everything.
Looping Through Multiple Store Batches with Cursor-Based Pagination
There might be only 50 restaurants available for your address, which the request above will easily be able to fetch the entirety of.
But if there are more than a 100 stores, DoorDash only loads a certain amount with the first call.
For the next batch(es) of restaurants and stores, it instead changes the cursor variable from the payload we copied before to tell the server to start the list from where it left in the request before.
This is called cursor-based pagination, and it’s very common in APIs powered by GraphQL.
💡 The cursor string is actually a base64-encoded JSON that has
"offset": 0and a few other variables in it that we can easily decode, change data, and encode again to send and get a successful response, but; the response already tells us what the next cursor is if there is any, so we can skip this step.
We’ll now write a full loop that:
- sends the request with our cursor
- parses the response
- stores the results
- extracts the next cursor
- and repeats until there’s nothing left
Let’s start from the top of our script with our setup:
import requests
import json
import csv
TOKEN = "<your-token>"
TARGET_URL = "https://www.doordash.com/graphql/homePageFacetFeed?operation=homePageFacetFeed"
SESSION_ID = "<session-id>"
API_URL = f"http://api.scrape.do/?token={TOKEN}&super=true&url={TARGET_URL}&sessionId={SESSION_ID}"
Then paste only the query string from the homePageFacetFeed request you copied earlier, we’ll include variables later:
QUERY = """query homePageFacetFeed($cursor: String, $filterQuery: String, $displayHeader: Boolean, $isDebug: Boolean, $cuisineFilterVerticalIds: String) {
homePageFacetFeed(cursor: $cursor filterQuery: $filterQuery displayHeader: $displayHeader isDebug: $isDebug cuisineFilterVerticalIds: $cuisineFilterVerticalIds) {
...FacetFeedV2ResultFragment
__typename
}
}
fragment FacetFeedV2ResultFragment on FacetFeedV2Result {
body {
id
header { ...FacetV2Fragment __typename }
body { ...FacetV2Fragment __typename }
layout { omitFooter __typename }
__typename
}
page { ...FacetV2PageFragment __typename }
header { ...FacetV2Fragment __typename }
footer { ...FacetV2Fragment __typename }
custom
logging
__typename
}
... (remaining fragments unchanged) ...
"""
That query tells DoorDash what kind of layout we want returned. It’s long and bloated, but we’ll only focus on one section from the response.
Now, let’s create the main scraping logic:
def main():
# Initial cursor for the first page of results
initial_cursor = "eyJvZmZzZXQiOjAsInZlcnRpY2FsX2lkcyI6WzEwMDMzMywzLDIsMyw3MCwxMDMsMTM5LDE0NiwxMzYsMjM1LDI2OCwyNDEsMjM2LDIzOSw0LDIzOCwyNDMsMjgyXSwicm9zc192ZXJ0aWNhbF9wYWdlX3R5cGUiOiJIT01FUEFHRSIsInBhZ2Vfc3RhY2tfdHJhY2UiOltdLCJsYXlvdXRfb3ZlcnJpZGUiOiJVTlNQRUNJRklFRCIsImlzX3BhZ2luYXRpb25fZmFsbGJhY2siOm51bGwsInNvdXJjZV9wYWdlX3R5cGUiOm51bGwsInZlcnRpY2FsX25hbWVzIjp7fX0="
cursor = initial_cursor
page_num = 1
count = 0
rows = []
That initial_cursor value is the exact value we saw in the original payload when visiting the homepage after setting our address. This tells DoorDash which section of the listing to return first.
Let’s now create our loop:
while True:
payload = {
"query": QUERY,
"variables": {
"cursor": cursor,
"filterQuery": "",
"displayHeader": True,
"isDebug": False
}
}
print(f"Requesting page {page_num}...")
try:
response = requests.post(API_URL, data=json.dumps(payload))
response.raise_for_status()
data = response.json()
except Exception as e:
print(f"Request or JSON decode failed: {e}")
break
Here we’re sending the same query on every loop, but with a different cursor. We use Scrape.do again as a proxy to avoid Cloudflare blocks, and parse the JSON like we did before.
Now we need to find the "store_feed" section inside the homepage body:
home_feed = data.get("data", {}).get("homePageFacetFeed", {})
sections = home_feed.get("body", [])
store_feed = next((s for s in sections if s.get("id") == "store_feed"), None)
if not store_feed:
print("No store_feed section found!")
break
If everything is successful, we now have the current batch of restaurant listings inside store_feed["body"].
We haven’t parsed any data yet and we’ll do that in the next section. But for now let’s just focus on cursor handling.
After each batch, we check for the next cursor:
page_info = home_feed.get("page", {})
next_cursor = None
if page_info.get("next") and page_info["next"].get("data"):
try:
next_cursor = json.loads(page_info["next"]["data"]).get("cursor")
except Exception as e:
print(f"Failed to parse next cursor: {e}")
break
if not next_cursor:
break
cursor = next_cursor
page_num += 1
That finishes our pagination loop and we’re now walking through every page DoorDash sends.
Parsing Each Store Entry into Structured Rows
Now let’s focus on what we’re actually pulling out of each page.
Each response contains a section called "store_feed" buried inside the "homePageFacetFeed" → "body" array. This is where DoorDash puts the real store listings.
We start by locating it:
home_feed = data.get("data", {}).get("homePageFacetFeed", {})
sections = home_feed.get("body", [])
store_feed = next((s for s in sections if s.get("id") == "store_feed"), None)
This gives us the part of the response with all the individual store entries.
Now we iterate over the rows inside that store feed.
But we don’t want to collect everything; we only want rows that represent real DoorDash stores.
We filter those with a simple check:
for entry in store_feed.get("body", []):
if not entry.get("id", "").startswith("row.store:"):
continue
Once we know we’ve got a valid store, we start parsing.
Each store entry is a big dictionary containing text, custom, and logging sections.
These hold info like store name, description, delivery time, and so on but some of them are already decoded dictionaries, and others are still JSON strings. So we use helpers to normalize them:
text = entry.get("text", {})
custom = extract_custom(entry) # Might be a dict or a stringified JSON
logging = extract_logging(entry) # Same here
With the text and metadata normalized, we construct a row:
row = [
text.get("title", "N/A"), # Store name
text.get("description", ""), # Store description
extract_custom_value(text.get("custom", []), "delivery_fee_string"), # Delivery fee
extract_custom_value(text.get("custom", []), "eta_display_string"), # ETA
custom.get("is_currently_available"), # Open now
custom.get("rating", {}).get("average_rating"), # Average rating
custom.get("rating", {}).get("display_num_ratings"), # Number of ratings
logging.get("price_range"), # Price range
logging.get("store_distance_in_miles"), # Distance in miles
custom.get("store_id") or logging.get("store_id"), # Store ID (fallback)
extract_link(entry) # Constructed from click event
]
Each of these fields corresponds to visible data on the DoorDash frontend, the info you’ll see when browsing.
We append each row into the rows list:
rows.append(row)
count += 1
And now our list contains every parsed store from every page.
Writing Everything Out to a CSV File
Now that we’ve collected all the store data into a list of rows, we just need to dump it into a CSV.
We’ll add this small section right after the QUERY bit to determine headers of our CSV file:
header = [
"Name", "Description", "Delivery Fee", "ETA", "Open Now", "Average Rating", "Number of Ratings", "Price Range", "Distance (mi)", "Store ID", "Link"
]
And we’ll make our code create and write to the CSV file and let us know in the terminal how many stores were listed:
with open("doordash_restaurant_listings.csv", "w", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
writer.writerow(header)
writer.writerows(rows)
print(f"Saved {count} stores to doordash_restaurant_listings.csv")
There are a few additions that we still have to make:
Complete the Code and Output
The bigger chunks of our scraper is done, some small parts that make it better we still need to add.
When starting our main function, we’ll initialize a few variables:
def main():
initial_cursor = "<cursor-goes-here>"
cursor = initial_cursor
page_num = 1 # For logging page progress
count = 0 # Track total store count
rows = [] # Final results container
We’re using page_num to track how many pages we’ve walked through, and we print it in each loop like this:
# Add right after we close the payload variables and before the try except statements where we send our POST requests
print(f"Requesting page {page_num}...")
And for the store ID, DoorDash sometimes puts it under custom["store_id"], sometimes under logging["store_id"]. So we use a fallback logic:
custom.get("store_id") or logging.get("store_id")
When all of these (and maybe a few more lines I’ve missed) are added, here’s what the full code looks like (with the payload omitted)
# Script to scrape DoorDash restaurant listings using the GraphQL API and save to CSV
import requests
import json
import csv
# API authentication and endpoint setup
TOKEN = "<your-token>"
TARGET_URL = "https://www.doordash.com/graphql/homePageFacetFeed?operation=homePageFacetFeed"
SESSION_ID = "<session-id>"
API_URL = f"http://api.scrape.do/?token={TOKEN}&super=true&url={TARGET_URL}&sessionId={SESSION_ID}"
# GraphQL query for fetching the home page facet feed
QUERY = "<full-query-payload>"
# CSV header for output file
header = [
"Name", "Description", "Delivery Fee", "ETA", "Open Now", "Average Rating", "Number of Ratings", "Price Range", "Distance (mi)", "Store ID", "Link"
]
# Helper to parse 'custom' field from entry, which may be a JSON string or dict
def extract_custom(entry):
val = entry.get("custom", "{}")
return json.loads(val) if isinstance(val, str) else val
# Helper to parse 'logging' field from entry, which may be a JSON string or dict
def extract_logging(entry):
val = entry.get("logging", "{}")
return json.loads(val) if isinstance(val, str) else val
# Helper to extract the store link from the entry's click event
def extract_link(entry):
events = entry.get("events", {})
data = events.get("click", {}).get("data")
if data:
try:
link_data = json.loads(data)
return link_data.get("domain", "") + link_data.get("uri", "")
except Exception:
return None
return None
# Helper to extract a value from a list of custom fields by key
def extract_custom_value(custom_list, key):
for c in custom_list:
if c.get("key") == key:
return c.get("value", "")
return ""
# Main scraping logic
def main():
# Initial cursor for the first page of results
initial_cursor = "eyJvZmZzZXQiOjAsInZlcnRpY2FsX2lkcyI6WzEwMDMzMywzLDIsMyw3MCwxMDMsMTM5LDE0NiwxMzYsMjM1LDI2OCwyNDEsMjM2LDIzOSw0LDIzOCwyNDMsMjgyXSwicm9zc192ZXJ0aWNhbF9wYWdlX3R5cGUiOiJIT01FUEFHRSIsInBhZ2Vfc3RhY2tfdHJhY2UiOltdLCJsYXlvdXRfb3ZlcnJpZGUiOiJVTlNQRUNJRklFRCIsImlzX3BhZ2luYXRpb25fZmFsbGJhY2siOm51bGwsInNvdXJjZV9wYWdlX3R5cGUiOm51bGwsInZlcnRpY2FsX25hbWVzIjp7fX0="
cursor = initial_cursor
page_num = 1
count = 0
rows = []
# Paginate through all available pages
while True:
payload = {
"query": QUERY,
"variables": {
"cursor": cursor,
"filterQuery": "",
"displayHeader": True,
"isDebug": False
}
}
print(f"Requesting page {page_num}...")
try:
response = requests.post(API_URL, data=json.dumps(payload))
response.raise_for_status()
data = response.json()
except Exception as e:
print(f"Request or JSON decode failed: {e}")
break
# Parse the main feed and find the section with store listings
home_feed = data.get("data", {}).get("homePageFacetFeed", {})
sections = home_feed.get("body", [])
store_feed = next((s for s in sections if s.get("id") == "store_feed"), None)
if not store_feed:
print("No store_feed section found!")
break
# Extract each store row from the feed
for entry in store_feed.get("body", []):
if not entry.get("id", "").startswith("row.store:"):
continue
text = entry.get("text", {})
custom = extract_custom(entry)
logging = extract_logging(entry)
row = [
text.get("title", "N/A"), # Store name
text.get("description", ""), # Store description
extract_custom_value(text.get("custom", []), "delivery_fee_string"), # Delivery fee
extract_custom_value(text.get("custom", []), "eta_display_string"), # ETA
custom.get("is_currently_available"), # Open now
custom.get("rating", {}).get("average_rating"), # Average rating
custom.get("rating", {}).get("display_num_ratings"), # Number of ratings
logging.get("price_range"), # Price range
logging.get("store_distance_in_miles"), # Distance in miles
custom.get("store_id") or logging.get("store_id"), # Store ID
extract_link(entry) # Store link
]
rows.append(row)
count += 1
# Check for next page cursor
page_info = home_feed.get("page", {})
next_cursor = None
if page_info.get("next") and page_info["next"].get("data"):
try:
next_cursor = json.loads(page_info["next"]["data"]).get("cursor")
except Exception as e:
print(f"Failed to parse next cursor: {e}")
break
if not next_cursor:
break
cursor = next_cursor
page_num += 1
# Write all collected rows to CSV file
with open("doordash_restaurant_listings.csv", "w", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
writer.writerow(header)
writer.writerows(rows)
print(f"Saved {count} restaurants to doordash_restaurant_listings.csv")
if __name__ == "__main__":
main()
And this is what your output CSV will look like:
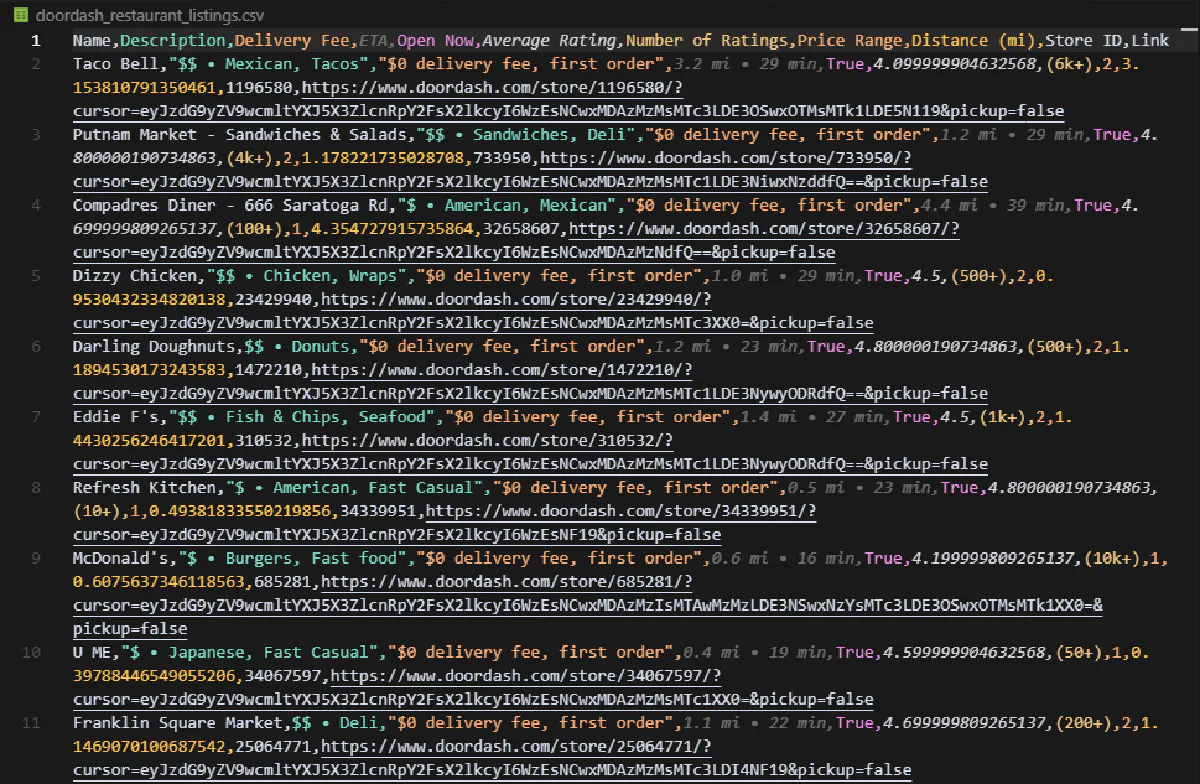
You’re now able to scrape restaurant listings wherever DoorDash is available!
Scraping Menu Items from a DoorDash Store/Restaurant Page
Unlike the homepage listings, individual DoorDash store pages don’t require any session ID or payload crafting.
⚠ This applies to local and small stores/restaurants only, not chain stores.
But still, it’s a relief.
The data is already there just buried inside a giant JavaScript blob at the bottom of the page.
Let’s see step-by-step how to extract it.
We’ll start by fetching the page using Scrape.do (with super=true to bypass Cloudflare), and parse the HTML with BeautifulSoup.
We’re scraping the entire menu of Denny’s in Brooklyn:
import requests
import re
import csv
import json
from bs4 import BeautifulSoup
TOKEN = "<your-token>"
STORE_URL = "https://www.doordash.com/store/denny's-saratoga-springs-800933/28870947/"
API_URL = f"http://api.scrape.do/?token={TOKEN}&super=true&url={STORE_URL}"
response = requests.get(API_URL)
soup = BeautifulSoup(response.text, 'html.parser')
Now here’s the tricky part.
DoorDash uses a JavaScript variable named self.__next_f.push(...) to fill the frontend with embedded JSON. Inside that structure lives everything we care about; menus, categories, item names, images, prices, and more.
We locate that script with:
menu_script = next(
script.string for script in soup.find_all('script')
if script.string and 'self.__next_f.push' in script.string and 'itemLists' in script.string
)
We then extract the raw embedded string using a regex:
embedded_str = re.search(
r'self\.__next_f\.push\(\[1,"(.*?)"\]\)',
menu_script,
re.DOTALL
).group(1).encode('utf-8').decode('unicode_escape')
This gives us a huge string of JSON-like content, but not in a form we can parse directly.
So we manually locate the "itemLists" array inside that string by finding where it starts with [ and where the matching ] ends:
start_idx = embedded_str.find('"itemLists":')
array_start = embedded_str.find('[', start_idx)
bracket_count = 0
for i in range(array_start, len(embedded_str)):
if embedded_str[i] == '[':
bracket_count += 1
elif embedded_str[i] == ']':
bracket_count -= 1
if bracket_count == 0:
array_end = i + 1
break
itemlists_json = embedded_str[array_start:array_end].replace('\\u0026', '&')
itemlists = json.loads(itemlists_json)
Now we’ve got a proper list of categories, each with a list of menu items.
Let’s loop through them and collect everything:
all_items = []
for category in itemlists:
for item in category.get('items', []):
name = item.get('name')
desc = item.get('description', '').strip() or None
price = item.get('displayPrice')
img = item.get('imageUrl')
Some items have a rating display string like 95% (132), which we’ll try to extract using regex:
rating = review_count = None
rds = item.get('ratingDisplayString')
if rds:
m2 = re.match(r'(\d+)%\s*\((\d+)\)', rds)
if m2:
rating = int(m2.group(1))
review_count = int(m2.group(2))
We then store all this info into a clean dictionary:
all_items.append({
'name': name,
'description': desc,
'price': price,
'rating_%': rating,
'review_count': review_count,
'image_url': img
})
Finally, we write everything into a CSV file:
with open('menu_items.csv', 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile,
fieldnames=['name','description','price','rating_%','review_count','image_url'])
writer.writeheader()
writer.writerows(all_items)
print(f"Extracted {len(all_items)} items to menu_items.csv")
And here’s what your output should look like:
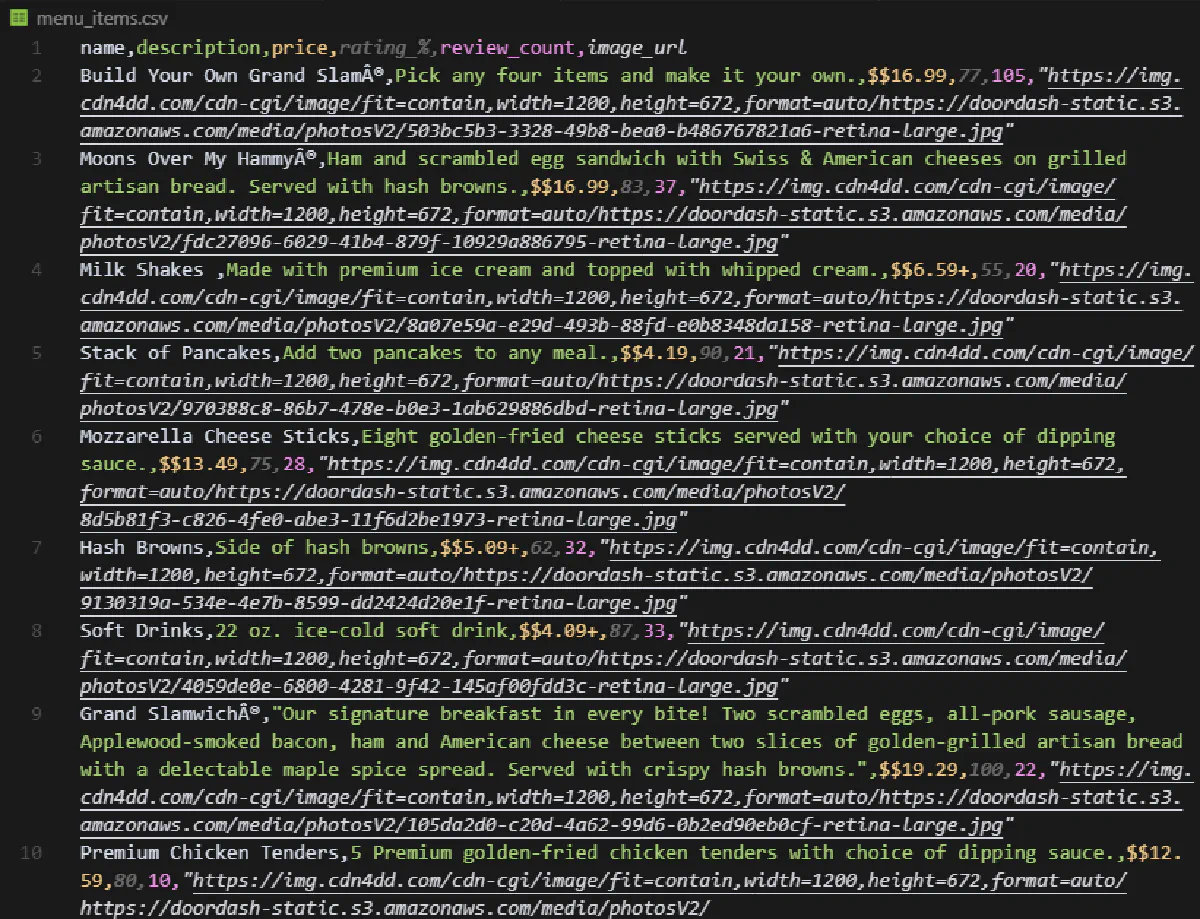
Scraping Products from DoorDash Categories (Grocery, Retail, etc.)
If you’re dealing with a large convenience store or retail chain on DoorDash like 7-Eleven, Walgreens, or Safeway, you won’t find a single screen that lists every item they sell.
There’s no all-in-one “store menu” like we had with restaurants.
Instead, DoorDash organizes retail products by categories such as drinks, snacks, medicine, frozen food, household supplies, and so on. And each of these is fetched individually from the backend using a different GraphQL query: categorySearch.
If you aim to get all the items a chainstore has available for a location you’ve picked, you’ll need to scrape each category and stitch them together.
Setting Up the GraphQL Query and Request Parameters
We’ll begin by setting up the essentials for sending a request to DoorDash’s category-level product API.
This is similar to what we did before, but this time the query targets the retailStoreCategoryFeed operation under the categorySearch endpoint.
We’re still using cursor-based pagination.
However, we need two additional values we’ll need to extract from a store’s URL.
When I select somewhere in Brooklyn as my address, I can view for example CVS, a chain grocery store in the US. And when I click on a the Drinks category, my URL becomes this:
https: //www.doordash.com/convenience/store/1235954/category/drinks-751;
I can extract what I need from here. storeId is 1235954 and categoryId is drinks-751.
Import the request libraries and paste in store and category values alongside your token, and session ID:
import requests
import json
import csv
TOKEN = "<your-token>"
TARGET_URL = "https://www.doordash.com/graphql/categorySearch?operation=categorySearch"
SESSION_ID = "<session-id>"
STORE_ID = "1235954"
CATEGORY_ID = "drinks-751"
API_URL = f"http://api.scrape.do/?token={TOKEN}&super=true&url={TARGET_URL}&sessionId={SESSION_ID}"
Then, closely observing the Network tab of the Developer Tools, find the categorySearch request and copy the query part of the payload.
Add the query string to your script, which will define what fields we want in return and which parameters we’ll be sending.
This one is slightly cleaner than the homepage feed, and we’re mostly interested in legoRetailItems, which contain the products:
QUERY = """query categorySearch($storeId: ID!, $categoryId: ID!, $subCategoryId: ID, $limit: Int, $cursor: String, $filterKeysList: [String!], $sortBysList: [RetailSortByOption!]!, $filterQuery: String, $aggregateStoreIds: [String!]) {
retailStoreCategoryFeed(
storeId: $storeId
l1CategoryId: $categoryId
l2CategoryId: $subCategoryId
limit: $limit
cursor: $cursor
filterKeysList: $filterKeysList
sortBysList: $sortBysList
filterQuery: $filterQuery
aggregateStoreIds: $aggregateStoreIds
) {
legoRetailItems { custom }
pageInfo { cursor hasNextPage }
}
}"""
This tells DoorDash to return all retail items in the given category, along with pagination info so we can fetch the next batch later.
We’ll build the loop and parsing logic in the next step.
Looping Through Paginated Product Batches in a Category
Just like restaurant listings, DoorDash product listings are also paginated, especially for chains with hundreds or even thousands of items in a single category.
We’ll use a cursor-based loop to go through each batch of items.
The cursor value gets updated on each response so we can request the next page. We start with an empty cursor and continue as long as hasNextPage remains true.
Let’s initialize our main logic and loop:
def main():
cursor = ""
page_num = 1
products = []
while True:
payload = {
"query": QUERY,
"variables": {
"storeId": STORE_ID,
"categoryId": CATEGORY_ID,
"sortBysList": ["UNSPECIFIED"],
"cursor": cursor,
"limit": 500,
"filterQuery": "",
"filterKeysList": [],
"aggregateStoreIds": []
}
}
print(f"Requesting page {page_num}...")
try:
response = requests.post(API_URL, data=json.dumps(payload))
response.raise_for_status()
data = response.json()
except Exception as e:
print(f"Request or JSON decode failed: {e}")
break
💡 In the original payload, the default limit variable is set as 50. But we changed it to 500 here to scrape 10X faster with 1/10 the amount of requests!
Here, we’re sending a new request on each loop with the current cursor. If DoorDash has more items, they’ll respond with a new cursor inside pageInfo.
Next, let’s grab the returned product batch and update the cursor if needed:
feed = data.get("data", {}).get("retailStoreCategoryFeed", {})
lego_items = feed.get("legoRetailItems", [])
for facet in lego_items:
prod = parse_product_fields(facet)
if prod[0]:
products.append(prod)
page_info = feed.get("pageInfo", {})
next_cursor = page_info.get("cursor")
has_next = page_info.get("hasNextPage")
if not has_next or not next_cursor or next_cursor == cursor:
break
cursor = next_cursor
page_num += 1
We’ve walked through all available product batches for that specific category. Now we need a parsing logic:
Extracting and Structuring Product Fields
Each product returned in the legoRetailItems list is a deeply nested dictionary filled with encoded JSON, optional fields, and redundant keys.
To make sense of it, we’ll write a helper function called parse_product_fields() that:
- Decodes the embedded JSON in the
customfield. - Extracts key metadata like name, price, ratings, image, and description.
- Returns a list of clean, human-readable values.
Let’s start by safely loading the JSON string:
def parse_product_fields(facet):
try:
custom = json.loads(facet.get('custom', '{}'))
except Exception:
custom = {}
From this decoded custom object, we pull a few key dictionaries:
item_data = custom.get('item_data', {})
price_name_info = custom.get('price_name_info', {}).get('default', {}).get('base', {})
logging_info = custom.get('logging', {})
image_url = custom.get('image', {}).get('remote', {}).get('uri', '')
These contain all the fields DoorDash uses to display products in its retail interface.
Now let’s extract and prioritize each value. We always prefer item_data first; if it’s missing, we fall back to price_name_info.
name = item_data.get('item_name') or price_name_info.get('name')
price = item_data.get('price', {}).get('display_string') or price_name_info.get('price', {}).get('default', {}).get('price')
reviews_count = logging_info.get('item_num_of_reviews') or price_name_info.get('ratings', {}).get('count_of_reviews')
reviews_avg = logging_info.get('item_star_rating') or price_name_info.get('ratings', {}).get('average')
stock = item_data.get('stock_level') or logging_info.get('product_badges')
image = image_url
description = logging_info.get('description')
Finally, we return these values as a list, which our loop appends to the main products list:
return [name, price, reviews_count, reviews_avg, stock, image, description]
With this function in place, each item in our CSV will be consistent, structured, and ready for downstream processing or analysis. Now let’s write the final part: exporting this data into a clean CSV file.
Exporting Products to CSV
Once we’ve looped through every product in the category and parsed its details, we’ll save everything into a CSV file just like we did before.
So here’s the complete code with the same CSV logic added:
import requests
import json
import csv
# Scrape.do API token and DoorDash GraphQL endpoint
TOKEN = "<your-token>"
TARGET_URL = "https://www.doordash.com/graphql/categorySearch?operation=categorySearch"
SESSION_ID = "<session-id>"
STORE_ID = "1235954"
CATEGORY_ID = "drinks-751"
# Build the Scrape.do API URL
API_URL = f"http://api.scrape.do/?token={TOKEN}&super=true&url={TARGET_URL}&sessionId={SESSION_ID}"
# GraphQL query for fetching category products
QUERY = """query categorySearch($storeId: ID!, $categoryId: ID!, $subCategoryId: ID, $limit: Int, $cursor: String, $filterKeysList: [String!], $sortBysList: [RetailSortByOption!]!, $filterQuery: String, $aggregateStoreIds: [String!]) { retailStoreCategoryFeed(storeId: $storeId l1CategoryId: $categoryId l2CategoryId: $subCategoryId limit: $limit cursor: $cursor filterKeysList: $filterKeysList sortBysList: $sortBysList filterQuery: $filterQuery aggregateStoreIds: $aggregateStoreIds) { legoRetailItems { custom } pageInfo { cursor hasNextPage } } }"""
# Helper to parse product fields from the GraphQL response
# Extracts name, price, reviews, stock, image, and description
def parse_product_fields(facet):
try:
custom = json.loads(facet.get('custom', '{}'))
except Exception:
custom = {}
item_data = custom.get('item_data', {})
price_name_info = custom.get('price_name_info', {}).get('default', {}).get('base', {})
logging_info = custom.get('logging', {})
image_url = custom.get('image', {}).get('remote', {}).get('uri', '')
name = item_data.get('item_name') or price_name_info.get('name')
price = item_data.get('price', {}).get('display_string') or price_name_info.get('price', {}).get('default', {}).get('price')
reviews_count = logging_info.get('item_num_of_reviews') or price_name_info.get('ratings', {}).get('count_of_reviews')
reviews_avg = logging_info.get('item_star_rating') or price_name_info.get('ratings', {}).get('average')
stock = item_data.get('stock_level') or logging_info.get('product_badges')
image = image_url
description = logging_info.get('description')
return [name, price, reviews_count, reviews_avg, stock, image, description]
# Main scraping logic
# Paginates through all category products and writes them to CSV
def main():
cursor = ""
page_num = 1
products = []
while True:
# Build the GraphQL payload for the current page
payload = {
"query": QUERY,
"variables": {
"storeId": STORE_ID,
"categoryId": CATEGORY_ID,
"sortBysList": ["UNSPECIFIED"],
"cursor": cursor,
"limit": 500,
"filterQuery": "",
"filterKeysList": [],
"aggregateStoreIds": []
}
}
print(f"Requesting page {page_num}...")
try:
response = requests.post(API_URL, data=json.dumps(payload))
response.raise_for_status()
data = response.json()
except Exception as e:
print(f"Request or JSON decode failed: {e}")
break
# Parse the product feed and extract product data
feed = data.get("data", {}).get("retailStoreCategoryFeed", {})
lego_items = feed.get("legoRetailItems", [])
for facet in lego_items:
prod = parse_product_fields(facet)
if prod[0]:
products.append(prod)
# Check for next page
page_info = feed.get("pageInfo", {})
next_cursor = page_info.get("cursor")
has_next = page_info.get("hasNextPage")
if not has_next or not next_cursor or next_cursor == cursor:
break
cursor = next_cursor
page_num += 1
# Write all products to CSV file
with open("doordash_category_products.csv", 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
writer.writerow(['name', 'price', 'reviews_count', 'reviews_avg', 'stock', 'image_url', 'description'])
writer.writerows(products)
print(f"Extracted {len(products)} products to doordash_category_products.csv")
if __name__ == "__main__":
main()
And here’s what the output looks like in the CSV:
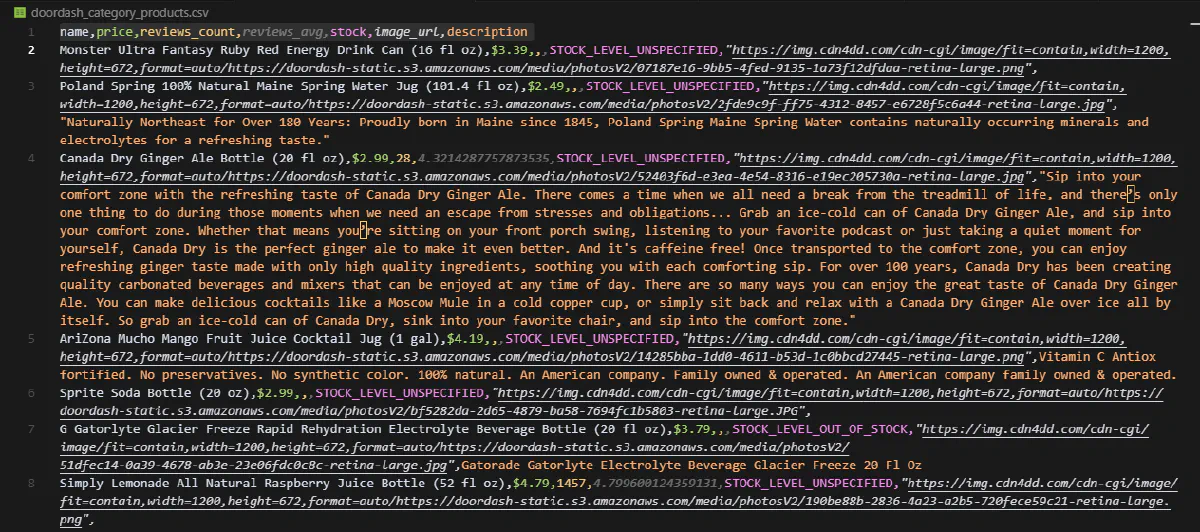
To Sum Up
DoorDash has one of the most complex and dynamic frontends of any delivery platform but as you’ve seen, that doesn’t mean it’s unscrapable.
By mimicking how DoorDash sets sessions, sends GraphQL mutations, and loads product listings in batches, you can extract local restaurant and store listings, entire menus from non-chain stores, and thousands of retail products by category from chain stores.
All with simple Python scripts.
And with Scrape.do, you don’t need to worry about:
- TLS fingerprinting, session spoofing, or rotating premium proxies
- Manual CAPTCHA solving or headless browser tricks
- Fighting Cloudflare that breaks your scraper every week
Just send the request and Scrape.do takes care of the rest.


R&D Engineer
Hey, folks! As someone who has managed to develop himself in the field of back-end software for years, I offer data interpretation and collection services for eCommerce practices to brands. I am sure that my experience in this field will provide you with useful information.